












Abstract
Background
Certain patient characteristics can elevate cancer risk, highlighting the need for personalized healthcare. For high-risk individuals, customized clinical management enables proactive monitoring and timely intervention. Electronic health record (EHR) data play a key role in supporting these tailored approaches, enhancing cancer prevention and early detection. In this work, we utilize EHR data to develop a predictive model for the early detection of non-small cell lung cancer (NSCLC).
Methods
We use electronic health record (EHR) data from Mass General Brigham and implement a three-stage ensemble learning framework. First, we apply multivariate logistic regression within both self-controlled and case–control study designs to generate individual risk scores for distinguishing cases from controls. Next, these risk scores are combined and calibrated using a prospective Cox proportional hazards model to build the final risk prediction model.
Results
We identified 127 EHR-derived features that are predictive of early NSCLC detection, with key contributors including smoking status, relevant lab results, and chronic lung conditions. The predictive model achieved an area under the ROC curve (AUC) of 0.801 (PPV: 0.0173 at 2% specificity) for estimating 1-year NSCLC risk in individuals aged 18 and older, and an AUC of 0.757 (PPV: 0.0196 at 2% specificity) for those aged 40 and above.
Conclusions
This study highlights the value of EHR-derived features in predicting early NSCLC diagnosis. The developed risk prediction model outperforms a baseline model that uses only demographic and smoking data, underscoring the potential of leveraging comprehensive EHR data to enhance personalized cancer screening and enable earlier detection.
Background
Cancer is the second leading cause of death in the United States, following heart disease, and late diagnosis significantly contributes to poor outcomes—especially in cancers like lung and pancreatic, where more than half of cases are diagnosed at a metastatic stage. In 2024 alone, there were an estimated 234,580 new lung cancer cases and 125,070 related deaths in the U.S. Although the five-year survival rate for lung cancer has improved—from 11.5% in 1975 to 26.7% in recent years—prognosis remains closely tied to the stage at diagnosis. Between 2014 and 2020, 22% of lung cancer cases were diagnosed at stages I–II, 21% at stage III, and 53% at stage IV, with corresponding five-year survival rates of 63.7%, 35.9%, and 8.9%, respectively. Early detection significantly improves survival, reduces treatment-related complications, enhances patient experience, and improves quality of life.
Lung cancer often presents without early symptoms, leading to delayed diagnosis. While established screening guidelines exist for cancers such as colorectal and breast cancer, lung cancer screening is currently recommended only for high-risk smokers. The U.S. Preventive Services Task Force advises annual low-dose CT scans for adults aged 50–80 with a 20-pack-year smoking history who currently smoke or quit within the past 15 years. Despite these guidelines, screening uptake remains low—less than 6% of eligible smokers were screened in 2015. Moreover, important groups such as younger individuals and non-smokers are excluded from current recommendations. As a result, there is a pressing need for risk prediction tools and screening strategies that use routinely collected healthcare data to improve early lung cancer detection across a broader population.
Clinical prediction models are increasingly used to support medical decision-making, and electronic health records (EHRs) provide a valuable source of real-world patient data for developing such models. While models like the PLCOm2012 have been influential, they rely heavily on detailed smoking histories that are often incomplete or inconsistently recorded in EHRs. Other recent efforts, including machine learning models developed for early NSCLC detection, have shown promising results but face limitations—such as being trained in retrospective case–control settings or incorporating predictors like prior cancer diagnoses, which may limit generalizability and clinical applicability.
In this study, we develop and prospectively evaluate a risk prediction model for early diagnosis of non-small cell lung cancer (NSCLC) using routinely collected EHR data. Our approach builds on a previously developed three-stage framework that integrates self-controlled, case–control, and cohort study designs. First, we use self-control and case–control analyses to address class imbalance and extract meaningful risk scores from high-dimensional EHR features. Next, we apply a cohort design to calibrate these scores and prospectively assess the model’s predictive performance. The goal of our model is twofold: to identify patients at elevated risk for NSCLC who may benefit from closer monitoring and screening, and to detect undiagnosed cases earlier, enabling timely referrals to specialized care. Additionally, we develop models to predict NSCLC across all stages, allowing us to compare predictive features between early- and late-stage diagnoses and gain deeper insight into how risk indicators vary by disease stage.
Methods
Study design
This study utilized two electronic health record (EHR) cohorts extracted from the Mass General Brigham (MGB) EHR databases. The first, known as the Lung Cancer (LC) data mart, consisted of lung cancer patients identified retrospectively using a validated machine learning algorithm. To confirm the accuracy of these algorithm-identified cases, manual chart reviews were performed on a randomly selected subset, successfully verifying the lung cancer diagnoses.
The second cohort was drawn from the MGB Biobank, which includes individuals enrolled from the broader MGB EHR population. Structured (codified) features—such as demographics, diagnoses, medications, laboratory results, and procedures—were extracted from the EHR. In addition, narrative features were derived using natural language processing (NLP) applied to clinical notes, capturing cancer-related information such as lifestyle factors (e.g., smoking, alcohol use) and other relevant health conditions. All NLP-extracted concepts were standardized using Concept Unique Identifiers (CUIs) from the Unified Medical Language System (UMLS).
Histologic type and tumor stage were inferred from clinical notes using a machine learning algorithm, with manual chart reviews conducted on a subset of cases to validate accuracy, which was found to be high. Socioeconomic features, such as the Social Vulnerability Index and the Area Deprivation Index at both national and state levels, were derived from patients’ five-digit zip codes.
Using these two complementary cohorts, this study implemented a three-stage, prospective–retrospective hybrid design developed by Li et al., combining multiple study designs to enhance early detection of lung cancer from EHR data.
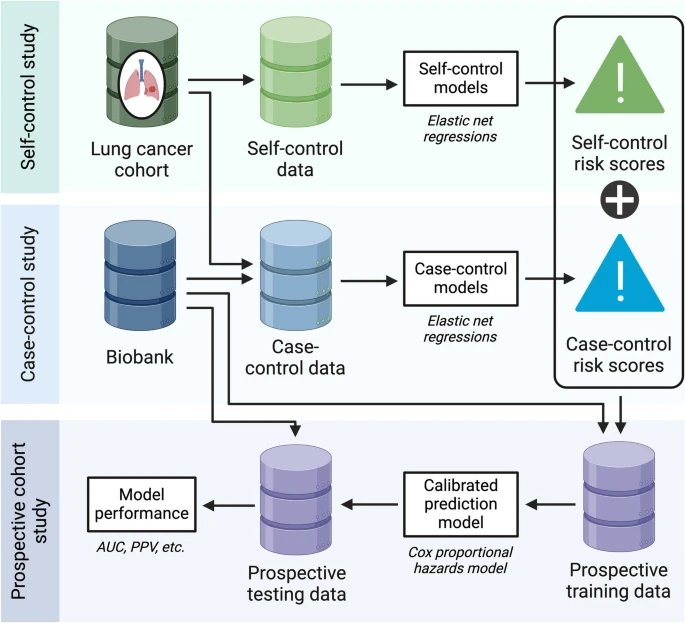
This study adopts a three-stage approach comprising the following components:
(i) a self-control design, which compares data from a pre-cancer window to a post-cancer window within lung cancer (LC) cases;
(ii) a case–control design, comparing LC cases to matched lung cancer–free controls; and
(iii) a prospective design, which integrates risk scores from the first two stages to build a final predictive model.
In the self-control design, we used an all-case cohort from the LC Mart, as defined in the Study Population section with specific inclusion and exclusion criteria. Two longitudinal time windows were established around each patient’s first NSCLC diagnosis: a cancer diagnosis window (the year leading up to diagnosis) and a pre-cancer control window (a year-long period beginning at least two years before diagnosis). By comparing these two windows—treated as “digital twins”—we controlled for individual-level confounding and identified temporal changes in predictive features.
The case–control design was used to identify features that are less sensitive to time. Each NSCLC case was matched with two lung cancer–free individuals from the MGB Biobank based on demographics (age, sex, race), healthcare utilization, and the calendar year corresponding to the control window. This design enabled the identification of features distinguishing cases from non-cases.
In both designs, we not only identified lung cancer–associated features but also trained classification models to generate risk scores that distinguish between cases and controls, as well as between pre-cancer and cancer diagnosis periods.
In the prospective modeling stage, we developed a final risk prediction model by integrating risk scores from the self-control and case–control models, using data from the MGB Biobank. For each calendar year from 2007 to 2021, we defined a cohort with a one-year feature window and set the outcome as time to lung cancer diagnosis within the following year. An ensemble learning technique was used to combine and calibrate the risk scores from the previous stages, enhancing the model’s predictive performance.
Study population
To construct the all-case NSCLC cohort, patients were selected from the LC Mart based on the following criteria: a confirmed diagnosis of lung cancer between January 2006 and December 2021; verified NSCLC histologic type and cancer stage; age 18 or older at first diagnosis; diagnosis after 2010 for inclusion in the self-control design and after 2007 for the case–control design; a minimum of 4 years of EHR data prior to diagnosis; no cancer diagnoses within the preceding 10 years; and available EHR records during both the pre-diagnosis and diagnosis periods. Patients were further stratified into early-stage (stages I–III) and metastatic NSCLC groups based on cancer stage at diagnosis.
For the case–control design, additional data were drawn from the MGB Biobank. Each NSCLC case was matched with two lung cancer–free controls based on diagnosis year, demographics (age, sex, race), and healthcare utilization. To support prospective modeling, yearly cohorts from 2007 to 2021 were also constructed from the MGB Biobank. Inclusion required enrollment in the Biobank, availability of at least one year of EHR data prior to January 1st of the cohort year, and no history of lung or other cancers in the 10 years preceding the cohort year.
Given the study’s focus on adult risk prediction, only individuals aged 18 or older at diagnosis were included. To ensure high-quality data, we limited the analysis to diagnoses after 2010 in the LC Mart and after 2007 in the MGB Biobank. Earlier data, especially before 2006, were excluded due to lower EHR completeness, including the absence of standardized electronic prescriptions. For the self-control design, we used up to four years of data prior to NSCLC diagnosis, while the case–control design utilized data from the year immediately before diagnosis. This approach ensured all data used for modeling fell within the post-2006 period and maximized cohort size.
To avoid bias from prior cancer surveillance, individuals with any cancer diagnosis in the 10 years before their NSCLC diagnosis were excluded. The goal of this selection process is to focus on identifying adults at elevated risk of developing NSCLC who may benefit from early detection and targeted intervention. A consistent four-year look-back period was required to align with the self-control design and support robust feature extraction.
Feature and outcome curation
To prepare EHR features and outcomes for modeling, all structured (codified) data were standardized and normalized into higher-level clinical concepts using established ontologies, enhancing clinical interpretability. Diagnostic codes were grouped into PheCodes based on the PheWAS catalog. Procedure codes were categorized into clinically meaningful groups such as “magnetic resonance imaging” using the Clinical Classification System. Medications were mapped to RxNorm categories, and laboratory tests were grouped according to LOINC (Logical Observation Identifiers Names and Codes). Narrative clinical data were processed using natural language processing (NLP) tools, such as the Narrative Information Linear Extraction (NILE) system, which extracts relevant clinical mentions as Concept Unique Identifiers (CUIs).
An initial set of codified features was generated using the Online Narrative and Codified feature Search Engine (ONCE), which creates a knowledge graph and semantic embedding vectors for a wide range of EHR concepts. These include codified terms like PheCodes and RxNorm, as well as NLP-derived concepts covering semantic types such as disorders and lab procedures. We selected features—both codified and NLP-derived—with a cosine similarity greater than 0.2 to the target disease concept (PheCode: 165.1, lung cancer). Additional NLP concepts were included based on input from clinical experts. A complete list of selected concepts is provided in Additional File 1. For each patient, the final set of features was extracted across the full observation window.
For each modeling design, predictive features were generated by computing the logarithmic total count of each concept within its respective time window. A healthcare utilization measure was also created by calculating the log total count of all integer-level PheCodes (diagnosis codes). The binary outcome variable was defined as 1 for lung cancer cases (or the diagnosis window in the self-control design), and 0 for controls (or the pre-cancer control window).
In the third stage—the prospective analysis—we split the MGB Biobank patients (excluding those in the case–control design) into two subsets: one for training the calibration model (calibration fold) and the other for evaluating model performance (evaluation fold). Yearly cohorts were created for each year from 2007 to 2021, allowing patients to appear in multiple cohorts if they met the inclusion criteria. For each cohort year, the preceding year served as the feature window. EHR features and healthcare utilization were aggregated using log counts from this window.
The outcome was defined as the time to NSCLC diagnosis within the following year. If no diagnosis occurred, or if follow-up was lost or the patient developed small cell lung cancer instead, the outcome was censored at year-end. Data from patients in the calibration fold were compiled across years to form a stacked calibration dataset, while data from the evaluation fold were similarly assembled to create an evaluation dataset for final model testing.
Statistical analyses
Feature screening
We began by conducting feature screening to identify informative variables for downstream modeling, using both the self-control and case–control designs. Feature frequencies were calculated separately for cases and controls, defined as the proportion of patients with a non-zero occurrence. Features were retained if they appeared in at least 1% of patients in either the case or control group within the relevant time window.
Next, marginal association screening was performed. In the self-control design, we fitted conditional logistic regression models, including one feature at a time as the covariate, adjusting for healthcare utilization and stratifying by patient. In the case–control design, standard logistic regression models were used, again including one feature at a time while adjusting for all variables used in the matching process. Features were selected based on p-values, and multiple testing was addressed by controlling the false discovery rate at 5% using the Benjamini–Hochberg method.
To prevent data leakage from features directly indicating a lung cancer diagnosis, we excluded variables such as CT scans, nodule-related findings, and associated diagnosis, procedure, medication, lab codes, and CUIs.
For laboratory tests represented by LOINC codes that passed marginal screening, we extracted the associated numeric values from the EHR and included them as additional features. To address missing values, we applied a last-observation-carry-forward method: if a lab value was missing during the cancer diagnosis or pre-cancer control window, it was replaced by the most recent value observed within the previous two years. If no value was available within that period, the lab result remained missing. Remaining missing values were then imputed using multivariate imputation by chained equations (MICE), with patient demographics and other numeric lab values included in the imputation model.
Model development
For both the self-control and case–control designs, classification models were developed using multivariate logistic regression. The predictor set included patient demographics (age, gender, and race), imputed lab values, indicators for missing lab values, log-transformed counts of EHR features (codes and CUIs) that passed marginal screening, and healthcare utilization metrics. To manage feature selection and regularization, an elastic net penalty was applied.
Five different tuning parameter values were used to balance between ridge and lasso regression, encouraging varying levels of sparsity in the models. The optimal penalty was selected through cross-validation. This process resulted in five classification models per design, yielding a total of ten risk scores for each patient based on a given time window.
In the third modeling stage, a Cox proportional hazards model was fitted to the prospective, calendar-year–specific cohorts using the ten risk scores, along with demographics and healthcare utilization as predictors. The model was stratified by 3-year calendar intervals to account for potential shifts in baseline hazard over time, capturing changes in lung cancer risk across periods. For benchmarking, a baseline model using only demographic and smoking data was also developed. Model performance was evaluated using the area under the ROC curve (AUC) and positive predictive value (PPV), calculated both overall and within each 3-year interval using the evaluation dataset.
The primary analysis focused on early-stage NSCLC patients aged 18 and older. Additionally, a subgroup analysis was conducted for patients aged 40 and above at diagnosis. This age threshold was selected to explore risk prediction in individuals younger than those currently targeted by standard screening guidelines, with the aim of identifying high-risk individuals who could benefit from earlier intervention and potentially greater life-year gains.
As part of a sensitivity analysis, we examined two alternative populations: (1) all NSCLC patients, including both early- and late-stage cases; and (2) patients aged 40 and above. Models for these groups were trained and evaluated using the same methodology described above.
Results
Construction of study sample
Self-control design
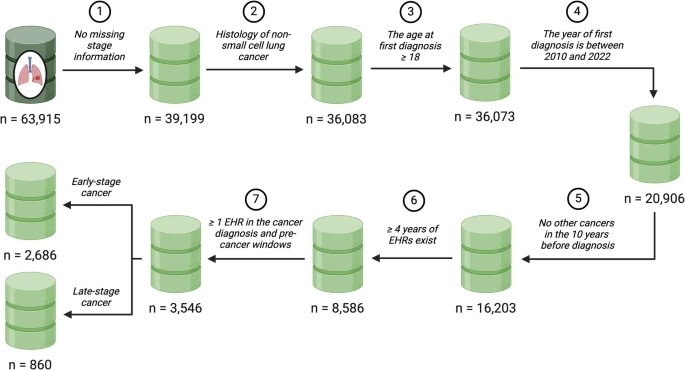
Of the initial 63,915 patients in the LC Mart, 3,546 met the eligibility criteria. Among these, 2,686 were diagnosed with early-stage NSCLC (stage I to III) at the time of their first lung cancer diagnosis, while 860 were diagnosed at the metastatic stage. Figure 2 outlines the selection process for the final study cohort. Table 1 summarizes the key characteristics of the eligible patients. For a broader overview of patient characteristics across the full lung cancer cohort, see Additional File 2: Table S1.
Discussion
By leveraging two electronic health record (EHR) cohorts from the MGB healthcare system, we identified EHR-derived features associated with early diagnosis of non-small cell lung cancer (NSCLC) and developed 1-year risk prediction models. These models outperformed a baseline model, achieving an AUC of up to 0.801 in individuals aged 18 and older, and an AUC of 0.757 in those aged 40 and above. In both populations, our models also demonstrated higher positive predictive value (PPV) compared to the baseline, suggesting improved identification of individuals at elevated risk who may benefit from targeted screening, monitoring, or preventive care. With further external validation, this model could support more efficient resource allocation and enhance clinical decision-making within a multi-stage cancer detection workflow. While we emphasized AUC and PPV in the primary results, additional performance metrics and sensitivity analyses are presented in Additional File 2: Table S6.
Our approach differs from previous EHR-based lung cancer prediction models in several key ways. First, our model was evaluated prospectively, enhancing its relevance for real-world clinical application. Second, we focused on early-stage diagnosis—aligning with the goal of detecting cancer at a more treatable stage. Importantly, our model excludes features that directly indicate lung cancer diagnosis (e.g., CT scans or nodule findings), ensuring it captures predictive patterns prior to clinical detection.
The model identified known risk factors, including older age, socioeconomic indicators, tobacco use, and chronic obstructive pulmonary disease (COPD). In addition, it highlighted EHR-derived signals such as respiratory symptoms (e.g., cough) and relevant laboratory test results, including platelet mean volume and neutrophil count—lab markers also reported in previous NSCLC prediction studies.
Our analysis also revealed low lung cancer screening rates in the year preceding diagnosis, with only a small proportion of patients having undergone screening. This finding points to the need for improving screening uptake and complementing existing guidelines with tools that can proactively identify high-risk individuals. The model performed well in patient groups not currently prioritized by standard screening recommendations, emphasizing its potential to enhance clinical screening strategies.
Several limitations should be noted. First, we were unable to directly compare our model to existing screening criteria or models like PLCOm2012 due to the lack of detailed smoking history, such as pack-years, which is not consistently available in structured EHR data or easily extracted from clinical notes. Additionally, model performance may vary over time and across healthcare systems, underscoring the importance of periodic evaluation and recalibration in new settings. External validation outside the MGB system was not conducted in this study and will be important for assessing generalizability.
We also observed that the proportion of early-stage NSCLC diagnoses in both the LC Mart and MGB Biobank was higher than typically reported in the general population. While this enabled us to train and test our model specifically on early-stage cases, the difference in stage distribution warrants further investigation, particularly regarding the model’s applicability beyond the MGB setting.
Although this study focused on NSCLC, the three-stage modeling framework we employed—incorporating self-control, case–control, and prospective cohort designs—can be adapted to build risk prediction models for a wide range of diseases. This design is especially well-suited for conditions with low incidence or limited case numbers in cohort data. The first two stages enrich for case data and help reduce dimensionality, while the cohort stage calibrates risk scores and enables rigorous prospective evaluation. Together, this approach offers a data-efficient, scalable strategy for developing and validating early detection models using routinely collected healthcare data.
Conclusions
This study employed a novel three-stage approach to identify EHR-derived features associated with early NSCLC diagnosis. The resulting risk prediction model outperformed a baseline model based solely on demographic and smoking data, demonstrating the added value of incorporating comprehensive EHR features. Notably, the model effectively identified high-risk individuals not captured by current screening guidelines, underscoring its potential to enhance existing lung cancer screening strategies and support earlier detection in clinical settings.
Abbreviations
EHR: Electronic health record
NSCLC: Non-small cell lung cancer
AUC: Area under the receiver operating characteristic curve
PPV: Positive predicted value
MGB: Mass General Brigham
LC: Lung cancer
NLP: Natural language processing
NILE: Narrative Information Linear Extraction
CUI: Concept unique identifier
UMLS: Unified Medical Language System
LOINC: Logical Observation Identifiers Names and Codes
ONCE: Online Narrative and Codified feature Search Engine
ROC: Receiver operating characteristics
MICE: Multivariate imputation by chained equations